

Memory organization
Last modified: 2016-02-29 (Added a link to stack/heap YouTube video)
The modern computer systems typically use virtual memory, that provides each process a dedicated memory space: each process sees only its own virtual memory space, and cannot access the memory of other processes. Even though each process sees a full 64-bit or 32-bit address space, typically only small portion of it is in use. If program tries to use an address from the virtual memory that has not been allocated for it, segmentation fault follows and the program terminates immediately. The virtual memory is divided into different segments, as shown below:
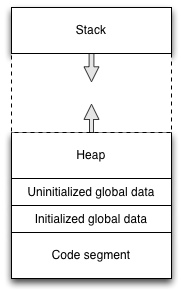
The program code is loaded from an ELF (Executable and Linking Format) formatted executable file into read-only code segment. The program code is produced as a result of compiling and linking process. When the program is started, the operating system starts executing the program from the code segment. Unlike with Java, Python or some other languages, there is not interpreter software between the system and the executable.
Constant strings are also located in the read-only area of the memory
space, and initialized when program is loaded. For example, when
declaring char *name = "Jaska";, string "Jaska" is allocated from
read-only memory (remember different ways of initializing a
string). Trying to modify such strings would raise segmentation fault
during program execution.
In addition to the code segment, memory space is allocated for
initialized global data and uninitialized global
data. Global data is for the variables that are declared outside
the program functions, and can be accessed from anywhere in the
program, or declared with the staticqualifier inside the
functions. The size of these segments are determined in advance, and
cannot be changed during program execution.
Heap is dynamically allocated memory: its usage varies based on the program execution. Program can allocate more memory from heap during its execution, and is expected to release the memory after it is not needed anymore. We have not yet used heap in our exercises and examples, but will see how heap is used in the next section.
Usage of the stack also varies during program execution, but it is allocated automatically by the computer system. Each time the execution enters a function, some space from stack is used: the return address to which the execution should return from the function is stored in stack. The function parameters are placed in stack. The space for local variables declared inside a function are also allocated from the stack. When function exits, the space it used from stack is released automatically. Therefore it is an error to refer to such memory from outside the function, even though use of pointers would technically allow this. The examples and exercises in Modules 1 and 2 have mainly used stack for the variables.
There is a useful video (approx. 17 min) in YouTube about stack and heap dynamics with a C program. It is recommended that you check it out at some point.
Dynamic memory management
Allocating and releasing memory
New memory from heap can be allocated using the malloc
function call, that is defined in stdlib.h header (like the
other memory management functions discussed below). The exact
definition for the function is void *malloc(size_t size). malloc()
takes one parameter that defines how many bytes of memory is
allocated. The function returns a pointer to the allocated memory. It
is possible that the return value is NULL (i.e. 0), which means that
the memory allocation failed. You should always check that the return
value is not NULL before starting to use the allocated memory. The
allocated memory is uninitialized, so you cannot assume anything about
its initial content.
The void* pointer in malloc return value is a generic pointer,
that is otherwise as any other pointer, but cannot be directly
dereferenced or used, because no type has been specified. Neither can
the pointer arithmetics be applied with void* pointer. However, it
is easy to assign (without explicit typecast) a generic pointer to
any typed pointer variable, after which it can be used normally. The
below example shows how this happens with the malloc return value.
After memory is successfully allocated using the malloc() call and the returned pointer assigned to a typed pointer variable, it can be used as any other pointer. For example, if malloc() was used to allocate an array of certain type, the normal array operators can be used to modify and access the content of the array.
Below is very simple example that allocates a buffer for 100 integers from heap, and fills it with numbers decreasing with 100:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | #include <stdlib.h> int main(void) { int *table; // uninitialized at this point table = malloc(100 * sizeof(int)); if (table == NULL) { return -1; // memory allocation failed } int i; for (i = 0; i < 100; i++) { table[i] = 100 - i; } free(table); } |
It is important to take the data type size into account when
allocating memory. In this case, we are allocating space for 100
integers. Therefore the size of the allocated memory needs to be
multiplied by the data type size, using the sizeof
operator (on line 6). Even though the array operator is not visible
in the table declaration, we are effectively using a
dynamically allocated array. In the above, after allocating space for
an array of 100 integers from heap, the array can be manipulated using
normal array operators (as on line 12).
In the end, the allocated memory is released using the
free function call. The call takes one parameter, the
pointer to the allocated memory. The allocated memory should always be
released after it is not needed. Otherwise a memory leak would follow,
meaning that your program would slowly consume increasing amount of
memory, leaving less memory for the other processes in the system. When
program terminates, the allocated memory is released by the operating
system, but memory leaks can be a problem in long-running processes,
for example in network servers.
An earlier allocated memory can be resized using the
realloc function. The exact definition of the function is
void realloc(void ptr, size_t size). ptr
is the pointer to the earlier allocated memory, size is
the new size (either smaller or larger than before). As with malloc,
the function returns pointer to the allocated memory. The returned
pointer may be different than what was given in the ptr
parameter. Logically this call is equivalent to 1) allocating a new
memory space of given size; 2) copying data from the earlier allocated
memory space to new one; 3) releasing the earlier allocated memory
space.
Below example shows how to use the realloc function, to cut the size of the earlier allocated array of 100 integers into half:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | #include <stdlib.h> int main(void) { int *table; // uninitialized at this point table = malloc(100 * sizeof(int)); if (table == NULL) { return -1; // memory allocation failed } int i; for (i = 0; i < 100; i++) { table[i] = 100 - i; } int *newtable = realloc(table, 50 * sizeof(int)); if (!newtable) free(table); // realloc failed, old pointer still valid else free(newtable); // realloc succeeded, old pointer is released } |
Using Valgrind
Valgrind is a toolkit for analysing various aspects in a program, and commonly used for finding memory management errors. Valgrind will tell about memory leaks, i.e., memory blocks that have been allocated but not released, memory access errors (e.g., some cases of reading/writing invalid address), and so on.
Valgrind is used at program run time: first, a C program will be
compiled and linked normally, to produce executable. Instead of normal
execution, the executable can be run under Valgrind by typing
valgrind name-of-executable on the command line. This
will cause Valgrind to produce output about any memory errors it
detects. If program is compiled with -g option (the exercise Makefiles
include this option), Valgrind will be able to point the line numbers
related to suspected errors. More information and instructions about
Valgrind memory checks can be found in their web
page.
Valgrind is commonly available on Linux distributions, but unfortunately, its availability on Mac and Windows is limited, although some Mac versions support Valgrind. Starting from Module 3 exercises, the TMC server will test the submitted code with Valgrind, and if there are Valgrind errors, the test will not pass, even if it had produced seemingly correct output in the local test.
We will now take a look for a couple of simple Valgrind error situations. Consider the following (badly implemented) function that will allocate some memory but the program will never release it:
1 2 3 4 5 6 7 8 9 10 11 12 | char *add_string(char *array, unsigned int *size, const char *string) { array = malloc(80 * (*size + 1)); if (array == NULL) { return NULL; } strncpy(&array[*size], string, 79); array[*size + 79] = 0; *size += 1; return array; } |
Valgrind will output:
1 2 3 4 5 6 7 | ==358== 80 bytes in 1 blocks are definitely lost in loss record 29 of 34 ==358== at 0x4C244E8: malloc (vg_replace_malloc.c:236) ==358== by 0x401C50: add_string (source.c:3) ==358== by 0x4014E9: test_moduli3 (test_source.c:13) ==358== by 0x404B70: srunner_run_all (in /tmc/test/test) ==358== by 0x401894: tmc_run_tests (tmc-check.c:99) ==358== by 0x4015E8: main (test_source.c:38) |
This message tells about memory leak ("blocks are definitely lost"), for a memory that was allocated by malloc function called in add_string function on line 3 in source.c. The error also shows the whole function call stack that leads to the error. With the TMC tests some functions from test_source.c and tmc_check.c are also shown, as in above example. This does not mean that these functions have an error, they are just functions that are used by the test framework, and were called prior to your function. The fix for this error is to free the allocated memory in some appropriate place of your code.
Sometimes freeing memory is not possible even when the code for releasing memory is properly implemented, for example if the pointer to the earlier allocated memory is lost. If a test fails with invalid result, and you hadn't yet implemented the code for freeing the memory, the test framework tries to help by releasing the memory for you. Sometimes this is not possible, for example, if a linked list is broken, and in addition to failure response in test, you will get a Valgrind error.
A slightly modified version of the above example will produce a different error:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | char *add_string(char *array, unsigned int *size, const char *string) { char *newarray = realloc(array, 80 * (*size)); if (newarray == NULL) { if (array) free(array); return NULL; } strncpy(&newarray[*size * 80], string, 79); newarray[(*size * 80) + 79] = 0; *size += 1; return newarray; } |
Now Valgrind will produce the following:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | ==358== Invalid write of size 1 ==358== at 0x4C25A4F: strncpy (mc_replace_strmem.c:339) ==358== by 0x401D33: add_string (source.c:10) ==358== by 0x401579: test_moduli3 (test_source.c:13) ==358== by 0x404C90: srunner_run_all (in /tmc/test/test) ==358== by 0x401924: tmc_run_tests (tmc-check.c:99) ==358== by 0x401678: main (test_source.c:38) ==358== Address 0x518c690 is 0 bytes after a block of size 0 alloc'd ==358== at 0x4C244E8: malloc (vg_replace_malloc.c:236) ==358== by 0x4C24562: realloc (vg_replace_malloc.c:525) ==358== by 0x401CE4: add_string (source.c:3) ==358== by 0x401579: test_moduli3 (test_source.c:13) ==358== by 0x404C90: srunner_run_all (in /tmc/test/test) ==358== by 0x401924: tmc_run_tests (tmc-check.c:99) ==358== by 0x401678: main (test_source.c:38) |
The strncpy function called on source.c line 10 in the
'add_string' function writes to an invalid, non-allocated location
in memory. Indeed, indexing the previously allocated array is done
wrongly, and strncpy tries to copy a string past the block of memory
that was allocated in earlier malloc call. ((*size - 1) * 80 might
have been better choice for strncpy, if *size is larger than
0). Again, Valgrind output shows the call stack of functions that were
called before the add_string function, that belong to the TMC test
framework. The error report also tells which malloc call allocated the
memory block that was invalidly accessed (on add_string, line 3 of
source.c). This does not mean that the malloc call itself has an
error, but because the invalid memory access could also be caused
because of invalid malloc call, this may be useful information.
It is fairly common that Valgrind shows repeated errors that refer to same lines. Once you find the reason for the error, many of the other error lines should go away.
Task 02_arrays_1: Dynamic Array Reader (1 pts)
Objective: Practice use of dynamic memory allocation with integer arrays
Implement function dyn_reader that allocates an int array for n integers. n is given as argument to the function when it is called. After allocating the array, the function should read the given number of integers to the array from user, using the scanf function. After the right amount of integers have been read, the function returns pointer to the dynamically allocated array.
Task 02_arrays_2: Add to array (1 pts)
Objective: Practice use of realloc together with array manipulation.
Implement function add_to_array that adds a single integer to the existing dynamically allocated array of integers (arr). The length of the existing array is num, and the new integer to be added is given in parameter newval. You'll need to ensure that array is extended to hold the additional integer. Check that the function works correctly when called several consecutive times.
Some memory management functions
The string.h header defines some functions for manipulating the
memory content that may be useful in different situations. The main
difference to the string functions discussed in Module 2 is, that
these functions do not care about the '\0' character that terminates
strings, and therefore work with any data content.
-
memcpy copies a block of memory to given address. The exact format is
void *memcpy(void *destination, const void *source, size_t n), where source points to the memory to be copied, destination points to where the block is to be copied, andntells the number of bytes to be copied. The function returns the value ofdestination. Remember to ensure that the destination memory block is properly allocated, before writing to it, although neither source or destination memory needs to be located in heap: they could be local variables or arrays allocated from stack as well. The source and destination memory areas cannot overlap. If they do, memmove should be used instead.< -
memmove is similar to memcpy, but also works when source and destination buffers overlap. The definition is also similar:
void *memmove(void *destination, const void *source, size_t n). -
memcmp compares the two blocks of memory. The exact format is
int memcmp(const void *mem1, const void *mem2, size_t n)where 'mem1' and 'mem2' are the two memory blocks to be compared, and 'n' is the size of the memory blocks in bytes. The function returns 0, if the two blocks are equivalent, or non-zero if they differ. -
memset fills the given memory block with given value. The exact form is
void *memset(void *mem, int c, size_t len). Heremempoints to the block of memory to be modified,lenis the size of the memory block in bytes, andcis the value that is set to every byte in the memory block. This function could be used, for example, to intialize an uninitialized memory block to zeros.
Here is an example that shows these functions in action:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 | #include <string.h> // memset, memcpy, memcmp, ... #include <stdlib.h> // malloc, free #include <stdio.h> // printf int main(void) { char *mem1, *mem2; mem1 = malloc(1000); if (!mem1) { printf("Memory allocation failed\n"); exit(-1); // no use continuing this program } mem2 = malloc(1000); if (!mem2) { printf("Memory allocation failed\n"); free(mem1); exit(-1); // terminating } memset(mem1, 1, 1000); memset(mem2, 0, 1000); if (memcmp(mem1, mem2, 1000) != 0) { printf("the memory blocks differ\n"); } memcpy(mem2, mem1, 1000); if (memcmp(mem1, mem2, 1000) == 0) { printf("the memory blocks are same\n"); } free(mem1); free(mem2); } |
Task 03_join: Join arrays (1 pts)
Objective: Practice use of memory management functions, and creating your source file and the related header definition from scratch.
Implement function join_arrays that gets three integer arrays as its arguments, and for each array the number of integers the array contains. The six function arguments should be in this order:
- number of integers in the first array (as unsigned integer)
- pointer to first array of integers
- number of integers in the second array (as unsigned integer)
- pointer to second array of integers
- number of integers in the third array (as unsigned integer)
- pointer to third array of integers
The function should join the three arrays into single array that contains all integers from the original arrays in the above order. The new array should be allocated dynamically, and the function should return the pointer to the created array. You must not modify the original arrays.
See example from main.c about how the function is called. In addition to source.c you will also need to modify source.h, so that the main function (and the tests) can find your function. Remember to include the needed headers. Note that in the beginning the code will not even compile, before you have implemented at least a some sort of placeholder of the join_arrays function that matches the interface that main.c assumes.
Data Structures
Related data can be collected together as structured data types. Structured data type can be assigned a name, so that it can be used for variables, function parameters, and so on. Structure may at first resemble the concept of object in object-oriented languages, but in C the functionality and data are separated: structures only contain the data, and functionality always happens by functions.
Defining structures
A new structure is declared using struct keyword. The structure contains fields using other datatypes that have been defined earlier. These can be the built-in basic data types, arrays, pointers, or other structured data types. Below is an example of simple structure definition, that contains two members: pointer to constant string name (note: this is just pointer, not an array), and integer for age. Because name is defined as constant, its content cannot be modified, but it can be re-assigned to another constant string, if needed.
1 2 3 4 | struct person { const char *name; int age; }; |
The above just declares the structure, but does not yet assign any variables to use it. It is also possible to define the variables at the same time:
1 2 3 4 | struct person { const char *name; int age; } guyA, guyB; |
After this, the program has two variables, guyA and guyB allocated, both of which have structured data type person as data type. The size of these two variables is (roughly) the sum of the members of the structure. The actual size can be checked using the sizeof operator.
Structure does not need to be named, so also the following would be possible:
1 2 3 4 | struct { const char *name; int age; } guyA, guyB; |
Named structures can be used later in the program to use
variables. For our structure "person", the following would then be
possible later in the code: struct person jussi; This
defines new variable "jussi", that uses structure person as the data
type.
Because in large software structures are often shared by multiple components, a common practice is to define the structures in .h header files, that could be included from the different .c source files that need to use the structure. Strcutures are also an essential element in many interfaces in system components. It is rare to define a structure inside a function, because that would limit its usability significantly.
Using structures
The records of the stucture are accessed using the member operator
.. The use of member operator is best clarified by an
example:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | #include <stdio.h> struct person { const char *name; int age; }; int main(void) { struct person lady = { "Kirsi", 22 }; struct person dude; dude.name = "Pertti"; // note "const char*" in the name field dude.age = 40; printf("name of lady: %s\n", lady.name); } |
The example shows two different ways of initializing a structure. Like
other variables, the structure content is undefined before
initialization (i.e., it is not necessarily 0). Structure can be
initialized using a initialization list, as in case of variable
lady above. Unlike with arrays, where the fields of the
initialization list all follow the same data type, the members in
structure initialization list must be compatible with the data types
of the structure members. The list follows the same order as the
fields in structure declaration.
The use of the member operator is demonstrated above in setting the
values for variable dude. In this case, the value of each
member needs to be assigned separately, otherwise the values of unset
fields will remain unspecified. Often it is a good idea to initialize
all fields to some predictable value, such as 0, that will help
debugging.
Unlike arrays, structures can be assigned between variables. For example the following would be proper code:
1 2 3 | struct person lady = { "Kirsi", 22 }; struct person dude; dude = lady; // what?? |
The above assignment is equivalent to memcpy(&dude, &lady,
sizeof(struct person));, but more convenient to use. Note that
the content of string is not copied, because it was defined as a
pointer. After assignment the two variables just point to the same
string, but because it is a constant string that will not be modified
during the program lifecycle, this is ok.
Structures can also be used as function parameters, similarly to other data types. Here is an example of function being called from inside the main function.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | #include <stdio.h> struct person { const char *name; int age; }; int has_enough_age(struct person p) { if (p.age >= 18) return 1; else return 0; } int main(void) { struct person guy = { "Kalle", 22 }; if (has_enough_age(guy)) { printf("You may enter!\n"); } } |
In the above example, the structure is passed by value, and there are no pointers involved. In other words, the all structure fields of variable lady is copied entirely to the function parameter p. Therefore, if the function would modify the structure content, the changes would not be visible in the main function. If we wanted a function that modifies the structure content, a pointer to the structure would need to be passed as function parameter, or the modified struture would need to be returned as return value.
Structure can be returned as the return value of the function using the return statement. This could be used as a tool to modify the structure content:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | int has_enough_age(struct person p) { if (p.age >= 18) return 1; else return 0; } struct person make_older(struct person p) { p.age++; return p; } int main(void) { struct person guy = { "Kalle", 15 }; while (!has_enough_age(guy)) { printf("waiting one year...\n"); guy = make_older(guy); } printf("age is now: %d\n", guy.age); } |
The above outputs:
1 2 3 4 | waiting one year... waiting one year... waiting one year... age is now: 18 |
Pointers to structures
As all data types, structures can be used with pointers. When
structure is used as a pointer, an alternative notation,
-> has been defined to access the structure
members. Below is an example of this usage, using the address operator
normally, as with any other data type.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | #include <stdlib.h> int main(void) { struct person lady = { "Kirsi", 15 }; struct person *kirsi = &lady; kirsi->age = 18; printf("age: %d\n", lady.age); struct person *guy; guy = malloc(sizeof(struct person)); guy->name = "Pertti"; guy->age = 40; free(guy); } |
The alternative pointer notation is used just as an easier variant
to (*kirsi).age, which becomes tedious especially with structures that
contain references to other structures (parentheses are required
because of precedence rules). The above function modifies the age in
variable lady, because 'kirsi' is a pointer to the same
record. Therefore lady.age shows as 18 in the printf
call.
The above example also shows a case of allocating the space for the
structure from heap instead of stack, as done for Pertti. The sizeof
operator can be used to determine the size of the structure, which is
the amount of memory we need to allocate. Note that this operator
should always be used instead of trying to calculate the size by
hand. The compiler may add empty spaces between the fields of the
structure. Therefore sizeof(struct person) may be
different than the sum of the field member sizes, sizeof(char *)
+ sizeof(int).
Pointer arithmetics work normally also with structures: when a pointer
to structure is increased by one, the address increases by the size of
the structure. Similarly, an array of structured data types can be
defined and used as normal. The below code plays with an array of
person structures. Note that for this example we changed the
definition of name from const char * to char * so that we
can dynamically allocate and build a name for each member in the
array, as done in the below code.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 | #include <stdio.h> #include <stdlib.h> #include <string.h> struct person { char *name; int age; }; int main(void) { struct person members[10]; struct person *current = &members[0]; int count = 0; char *nameprefix = "guy-"; const int NameLen = 5; /* Need to allocate name separately, because structure does not reserve space for it */ for (int i = 0; i < 10; i++) { members[i].name = malloc(NameLen + 1); // if malloc does not succeed, name remains unspecified if (members[i].name) { /* Dynamically build unique name for each member: "guy-A", "guy-B", "guy-C", .... */ strcpy(members[i].name, nameprefix); members[i].name[4] = 'A' + i; members[i].name[NameLen] = '\0'; } members[i].age = i + 60; } // find first person who is at least 65 years old /* could also use: members[count].age */ while (count < 10 && current->age < 65) { current++; // move to next element in array count++; } // in principle we might have not succeeded allocating all names // therefore current->name could be NULL if (count < 10 && current->name) { printf("found: %s, age: %d\n", current->name, current->age); // or: printf("found: %s", members[count].name); } // remember to release allocated memory for (int i = 0; i < 10; i++) { if (members[i].name) free(members[i].name); } } |
The above example creates ten persons, who are named guy-A, guy-B,
..., guy-J. The space for name string needs to be allocated for each
person separately, because the structure has not allocated the space:
it only contains a pointer to the name. If the structure member itself
had been defined as an array of characters, for example char
name[20];, the space for the string would have been allocated
as part of the structures in array, and dynamic allocation would not
have been needed. The above example also shows different alternative
ways of accessing the elements in array, either using the indexing
operator, or a pointer that follows through the array.
Forward declaration
It is possible for structures to refer to other structures. However, in order to use a data type, it must have been declared before. Sometimes, with more complicated set of cross-references it may be impossible to declare everything in the right order. In such case a forward reference is needed, to satisfy the compiler and tell that the data type definition will be coming. Below is an example of a forward reference of structure pet, that is needed, becayse person refers to it:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 | #include <stdio.h> struct pet; struct person { const char *name; int age; struct person *marriedTo; struct pet *myPet; }; struct pet { struct person *owner; const char *name; }; int main(void) { struct person man = { "Jorma", 50, NULL, NULL }; struct person lady = { "Kirsi", 15, &man, NULL }; struct pet cat = { &lady, "Kisu" }; man.marriedTo = &lady; lady.myPet = &cat; printf("Name of the cat: %s\n", man.marriedTo->myPet->name); } |
In the above we extend our person structure by two new fields, that
are pointers to other structures. Structure pet needs a
forward declaration, because its actual declaration comes only after
the person structure. Forward declaration is in the beginning: it
looks like an empty declaration. Note that changing the order of the
structure declarations does not help, because pet has pointer also to
the person structure. With this kind of cyclic declarations only
pointers can be used, and the example below would be impossible:
including a full pet structure inside person structure would
not make sense, because pet structure itself contains the
person structure, that contains the pet structure, and so on...
1 2 3 4 5 6 7 8 9 10 11 | struct person { const char *name; int age; struct person marriedTo; struct pet myPet; }; struct pet { struct person owner; const char *name; }; |
This would cause the space of the other structures be allocated from inside the person structure, but before the actual structure declaration of pet the compiler does not know how much space is needed.
In the main function above, not all values can be included in the
initialization list: at the time on initializing man, the
variable lady is yet unknown to the compiler. Therefore
some of the structure members need to be declared afterwards.
Task 04_vessel: Defining a ship (1 pts)
Last modified: 2016-03-11 (Couple of words about pointers and use of malloc)
Objective: Practice definition of structures, and their basic use.
In this exercise you will need to implement three things to earn a point 1) define a vessel structure; 2) implement function create_vessel that creates a new vessel structure instance; and 3) implement function print_vessel that prints the contents of the vessel structure.
The vessel structure must have the following fields. It is important that the names are correct, otherwise src/main.c nor the test code will not compile.
-
name: name of the ship as a string. The string must be copied from function parameter p_name, you cannot directly assign it. The name must be modifiable, and there must be room for up to 30 characters in name (plus the ending character '\0'). If the name given as function parameter is longer than 30 characters, it should be truncated to 30 characters long.
-
length: length of the ship as double floating point number (you could assume these are meters)
-
depth: depth of the ship as double floating point number (you can assume meters, but that's not important)
-
crg: cargo of the ship. This is equivalent to the content of one cargo structure that is given in source.h
The vessel structure should be defined in source.h so that the other source files can find it.
create_vessel gets the same arguments as the vessel struct members, and you should use these when creating a new vessel structure. Pay attention to how the string argument (name) is going to be handled: the string must be copied.
NOTE: create_vessel returns a copy of your vessel data structure, which is not a pointer. The code that is outside of the function cannot free any memory that you have allocated, so using malloc will cause a memory leak (unless you release the memory right away, which is not sensible). Think whether you need pointers at all in this exercise.
print_vessel prints the vessel struct contents, each structure member in its own line, including the members of the cargo structure. The double type fields should be printed at the precision of one decimal. For example, after the functions are properly implemented, the example program in src/main.c would print:
Apinalaiva 180.0 8.5 Bananas 10000 1500.0
Abstract Data Types
Often a good programming practice is to hide details of data management into abstract data types that allow the handling only through a published interface, that hides the internal implementation is not exposed. This allows different implementations (or different algorithms) for operating the data type, while the implementation details remain hidden from the users of the interface. This also makes evolution of implementations easier, because changes on one side of the interface do not require modifications on the other.
The C language does not provide built-in mechanisms for abstract data types, but they are implemented by coding conventions and particular use of C headers, together with the typedef declaration that allows elegant representation of the types.
The public header of an abstract data type defines the interface (functions, data types, constants) that can be used to access the data type, but typically does not have to reveal the internal composition or operation of the data, because the user of the interface is typically not supposed to access it directly. Below is an example of a Vector type that can be used to handle euclidean vectors familiar from mathematics. The defintions would be given in a separate header file "vector.h".
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | #ifndef AALTO_VECTOR_H #define AALTO_VECTOR_H /* Define Vector type to be used in interfaces, but don't show its internal structure */ typedef struct vector_st Vector; /* Allocates a new vector from heap, returns pointer to the vector */ Vector* vectorCreate(double x, double y, double z); /* Releases the vector from heap */ void vectorFree(Vector *v); /* Calculates sum of two vecors. Result is returned in new vector object allocated from heap */ Vector* vectorSum(const Vector *a, const Vector *b); /* Calculates the length of the vector */ double vectorLength(const Vector *v); /* Prints the vector to standard output */ void vectorPrint(const Vector *v); #endif // AALTO_VECTOR_H |
This is also an example of an include guard: the #ifndef and #define precompiler instructions are used to ensure that the same definitions are not included multiple times during single compilation process, which would lead to compile errors due to duplicate declarations. This could happen with larger programs with nested include dependencies (the precompiler functionality will be discussed in later modules). Then, a forward declaration of struct vector_st is done, with a typedef mapping to Vector data type. The header also defines function interfaces for operating the vector. Note that the public header does not tell anything about how struct vector_st is defined, or how functions are implemented. The usage of const qualifier is also important in function interfaces: it is used to tell the calling program that the functions are not going to modify the value of vector.
Next, the implementation of vector is given in C source file (let's call it "vector.c"). The users of vector do not need to know how operations are implemented, and they might not even have access to the source code, although an object file or library of the implementatioin is needed in order to build running program. Here is part of the vector implementation:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 | #include <assert.h> #include "vector.h" // to ensure that the interface is compatible struct vector_st { double x, y, z; }; Vector* vectorCreate(double x, double y, double z) { Vector *v = malloc(sizeof(struct vector_st)); v->x = x; v->y = y; v->z = z; return v; } void vectorFree(Vector *v) { assert(v); // fails if v is NULL free(v); } Vector* vectorSum(const Vector *a, const Vector *b) { assert(a); // check that value is not NULL assert(b != NULL); // other way to check that value is not NULL Vector *ret = malloc(sizeof(struct vector_st)); ret->x = a->x + b->x; ret->y = a->y + b->y; ret->z = a->z + b->z; return ret; } /* ...continues with some other Vector management functions... */ |
The above implementation uses the assert macro for checking that the pointers passed to functions are not NULL (which would indicate some sort of error in calling code). The macro is defined in "assert.h" header, and can be used to verify given conditions (assertions) about the variables. If assert condition fails, the program aborts showing the location of failing assertion. Asserts are a good tool for verifying strong assumptions about the parameters passed to the interface, when failure should be considered an error in the program that uses the interface.
The other parts of C source (in different C source files) can use the vector interface as defined in "vector.h". It is sufficient for the other parts of the source to just see the vector.h header. After the compiler makes object files of each C source file, the linker combines them into single executable. The internal vector implementation can be modified in "vector.c", and the other parts of the code do not need to be modified, as long as the interface remains unchanged.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | #include "vector.h" int main(void) { // create two vectors and calculate their sum into third vector Vector *v1 = vectorCreate(1, 3, 4); Vector *v2 = vectorCreate(0, -2, 2); Vector *v3 = vectorSum(v1, v2); // print the result vectorPrint(v3); // release all three vectors that were allocated vectorFree(v1); vectorFree(v2); vectorFree(v3); } |
Task 05_fraction: Fraction (4 pts)
We practice abstract data types by implementing a new number type,
fraction, that consists of numerator and denominator. For example
2/3 and 4/6 are equivalent values, where 2 and 4 are numerators, and 3
and 6 are denominators. A new data type, Fraction is used to
represent fractions.
Implement the following functions. In this exercise, you are only given header fraction.h that specifies the public interface. fraction.c is nearly empty, and you will need to implement everything, starting from the definition of struct fraction_st.
(a) Set value
Implement function Fraction* setFraction(unsigned int numerator,
unsigned int denominator) that allocates a new Fraction from heap,
sets its value as given in parameters, and returns the created object.
In addition, implement also the following simple functions
-
void freeFraction(Fraction* f)that releases the memory used by the Fraction. -
unsigned int getNum(const Fraction *f)that returns the numerator part of the fraction. -
unsigned int getDenom(const Fraction *f)that returns the denominator part of the fraction.
(b) Compare values
Implement function int compFraction(const Fraction *a, const
Fraction *b) that returns -1 if a < b, 0 if a == b, or 1 if a > b.
The function should work correctly also when denominators are
different.
Note: The local tests for the following parts of this exercise use this function to test the outcome. Therefore it is recommended that you implement this part before (c) and (d). If you get silly error message incorrectly complaining about wrong result in them, the reason might be incorrect compare implementation. The tests on (c) and (d) on TMC server do not depend on your comparison code.
(c) Add values
Implement function Fraction *add(const Fraction *a, Fraction *b)
that adds values 'a' and 'b', and returns the result in a new
object allocated from heap. Again, the denominators may be different
in the two numbers. The resulting value does not need to be
reduced to smallest possible denominator.
Hint: start by modifying the two numbers such that they have the same denominator.
(d) Reduce value
Implement function void reduce(Fraction *val), that reduces the
value to the smallest possible denumerator. For example, using this
function 3/6 should reduce to 1/2. For doing this, you'll need to find
the greatest common divisor for the numerator and denominator. The
exercise template contains function unsigned int gcd(unsigned int u,
unsigned int v) (source:
wikipedia), that
you can use from your function.
Task 06_oodi: Oodi (3 pts)
Objective: Practice use of data structures, as a member of dynamically allocated (and re-sized) array.
Implement a simplified database for storing course grades. Each
database record is specified as struct oodi, and the database is
built as a dynamically allocated array, that contains a number of
consecutive struct oodi instances in a contiguous positions in
memory that needs to be dynamically allocated. Every time a new
element is added to the array, it needs to be reallocated to have
sufficient space for all entries.
struct oodi definition, and the purpose of each field in the
structure are defined in file oodi.h. Pay attention to which
structure members are allocated as part of the structure definition,
and which need to be allocated separately. For example, member
course is a dynamically allocated string.
The exercise consists of 4 subtasks, each worth of one exercise point as follows. It is recommended that you implement the subtasks in order, because tests of later subtasks depend on the earlier implemented functions. You can also test and submit the exercise after each subtask, to make testing easier, and to gain part of the points.
(a) Initialize student record
Implement function 'init_record' that initializes an struct oodi
instance pointed by parameter 'or'. The structure does not need to
be allocated from by this function, but the allocation is done
elsewhere. However, you need to allocate needed memory for those
structure fields that need to be allocated separately.
The function returns 1, if initialization was successful, and 0 if it did not succeed. Initialization fails if function is called with invalid student ID. Invalid student ID has more than 6 characters. You can assume that any other other student ID with 6 characters or less is valid.
(b) Add new record
Implement function 'add_record' that adds a new struct oodi record to the dynamic array, and reallocates the array as needed. The start of the dynamic array is given in parameter 'array', and the current length of the array is given in parameter 'length'. The new information to be added is given as parameter 'newrec'. Note that the content of newrec needs to be copied to the array. Pay attention to which parameters are pointers and which are not.
The function returns address to the dynamic array after the addition. This may be same or different than the pointer given in 'array' parameter.
(c) Change grade
Implement function 'change_grade' that changes the grade ('newgrade') and completion date ('newdate') in one of the existing records in the array. The record to be changed is identified by student ID ('p_code') and course code ('p_course'). If no record with matching student ID and course code are found, nothing is changed. The function returns 1, if a change was made, and 0 if no matching records were found. You can assume that there are no multiple entries with same student ID and code.
Linked list
Linked list is a common data structure based on dynamically allocated nodes linked with pointers between the nodes. There are different variants of linked lists, but here we discuss a basic list with a pointer to the beginning of the list, and each member of the list containing a pointer to the next member of the list.
Let's assume a linked list that stores integer values. Each list member is defined by the following structure:
1 2 3 4 | struct intlist { int value; struct intlist *next; }; |
The list consisting of the above kind of nodes looks like this:
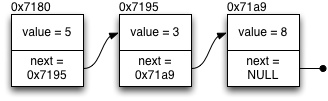
When processing through the list, an implementation has to have a pointer to the first member of the list, and then walk through the list by following the next pointers. For example, the following code prints all values in the linked list.
1 2 3 4 5 6 7 8 9 | struct intlist *first; // do something to initialize the list... struct intlist *current = first; while (current) { printf("value: %d\n", current->value); current = current->next; } |
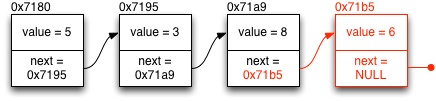
When adding a new member to the end of the list, the following steps need to be taken:
-
Allocate memory for a new list node:
struct intlist *new = malloc(sizeof(struct intlist));. Initialize the members of the allocated structure. Because the new member will be the last element of the list, the next pointer will be NULL. -
Find the last member of the list. The last member is the one that has
current->next == NULL -
Modify the next link of the last member to point to the newly allocated member. (
current->next = newor something like that). Now the new member is at the end of the list.
The same illustrated as diagram:
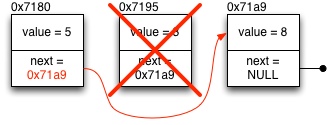
When a list member is removed from the list, the next pointer of the previous member needs to be modified to bypass the member to be removed, and point to the following list member. Naturally, the memory allocated for the removed member needs to be released.
When processing the linked list, it is good to pay attention to the special cases at the first member of the list (or when adding an element to empty list) and the last member of the list. Sometimes they may need special attention.
Task 07_queue: Exercise queue (3 pts)
Objective: Practice structure and pointer manipulation together with linked list, a common data structure in C programs.
This exercise implements a simple queue that holds student IDs and names. The queue is implemented as an abstract data type 'Queue', and the functions to operate the queue are in file 'queue.c'. 'queue.h' defines the public interface to the queue, and 'queuepriv.h' contains definitions that are internal to the queue and should not be directly accessed from elsewhere than 'queue.c'. The queue is implemented as a linked list.
This variant of linked list has the pointer to the first member of the queue, and another pointer to the last member of the queue, in addition to the next pointers with each member that allow traversing through the linked list. The next pointer of the last member in the queue should always be NULL.
Initially, pointers 'first' and 'last' are NULL. When the list has only one member, both 'first and 'last' point to the same address. With longer lists they are different. Each new list member should be dynamically allocated, and linked to the end of the list by replacing the NULL pointer with the address of the new element (and updating the 'last' pointer. The new element, in turn, will have NULL as its next pointer.
Walking forward along each member of the linked list happens by
following the 'next' pointers. After finding the last element
(q->next == NULL), you will need to modify the pointer, to connect
the newly allocated node to the list (i.e., assigning the pointer you
received from dynamic memory allocation).
Some of the functions for handling the 'Queue' type are already implemented, but the most important operations are missing. You should implement the following functions for the linked list.
(a) Add student to queue
Implement function 'Queue_enqueue' that adds a new student with given student ID and name to the end of the queue. The function returns 1 if addition was successful, or 0 if not. If student ID is invalid (more than 6 characters), the function should not add anything, and return 0. Because the length of the name is not known, the space for it needs to be allocated dynamically. Also the space for the new queue element needs to be dynamically allocated.
You do not need to check whether the given student is already on the queue.
For easier debugging, it is advised that you test your code first using the main.c executable, before giving it to the TMC tester.
(b) Remove the head of the queue
Implement function 'Queue_dequeue' that removes the first member
of the queue, and releases all memory allocated for it. The function
returns 1, if something was removed; or 0 if nothing was removed,
i.e., because the queue was already empty. This way, the whole queue
can be removed by while (Queue_dequeue(queue));.
(c) Drop a specific member from queue
Implement function 'Queue_drop' that removes the given student (as identified by student ID) from the queue, and releases memory allocated for it. This queue member can be located anywhere in the queue, and after removal, the queue should remain operational, i.e., all the pointers should be updated accordingly.
The function returns 1, if student with matching ID was found and removed, and 0, if there was no match, and nothing was removed. Each call should remove only one queue member: if a student is on the queue several times, only the first entry is removed.